

MVP to Production AI
Optimize and Scale Your AI Agent's Tool Calling
Improve your AI agent's tool calling. We go over how to measure performance, how to improve, and how to scale the number of tools for your agent.
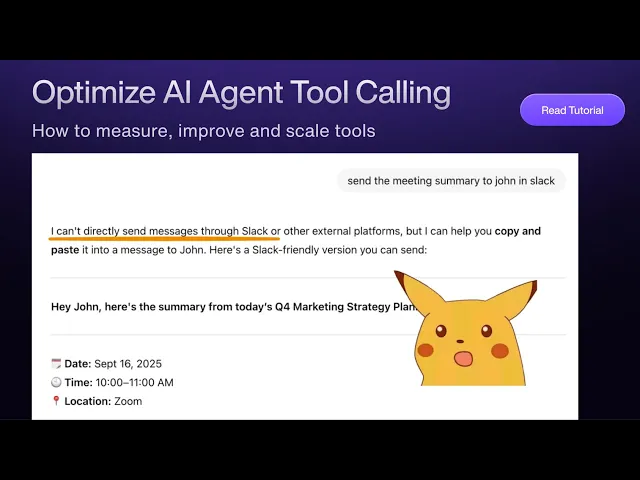
You have an AI agent that can call tools to search the web and call APIs. Your team rejoices! Hold on… Why did the agent call the tool successfully here and not there?

This universal experience (aka frustration) we’ve all had building and using AI agents naturally leads us down the path of improving tool calling.
In this deep dive, we’ll go over:
What it means to be “good” at tool calling
How to improve tool calling
Why agents struggle with tools at scale
How to implement tools at scale
Video Walkthrough
What it means to be “good” at tool calling
Reviewing AI responses can be like reviewing a movie. Whether or not you liked a movie is partly objective, but also part subjective taste. Evaluating tool calling is no different. That being said, there are two main metrics to measure tool performance:
Tool correctness
Task completion.
Tool Correctness
Tool Correctness measures if the agent selected the right tool/set of tools using an objective measure of if a tool was called or not called (1). It’s not subjective. It’s a straightforward statistic.

Here’s an example. A Cursor user building a web UI asks for Cursor to make their sidebar collapsible. The Cursor development team may define the expected tools for this task to be the READ CODE tool, EDIT CODE tool and the LINT tool.


Task Completion
Task completion assesses end-to-end success on the prompted task. An LLM judge (while a bit subjective) provides the score that quantifies to what extent the job was completed using tools. Here is DeepEval’s methodology for task completion (1).

In the Cursor example:

In summary, tool correctness is a proxy for “the agent is calling the right tools.” Task completion is a proxy for “the agent is using tools correctly to answer the user’s prompt.“ Both are necessary for a production-level agent. Let’s talk about how to improve your tool correctness and task completion scores.
How to improve tool calling
The main settings that affect tool calling performance are:
LLM choice
System prompts
Number of tools to choose from
Tool description quality
We ran evaluations on a series of test cases where we varied each setting across 50 test cases (2). A majority (36/50) of these test cases were defined to test just one specific tool. Fourteen of our test cases involved chaining multiple tools. Here are a few examples:

High-level takeaways
The takeaways from our tests reveal that LLM choice has the largest impact on tool calling performance. This makes sense, as model providers like OpenAI and Anthropic have set their sights on building better models for tool calling.

The other settings saw either negligible or mixed effects on tool performance.

In the weeds
You may be thinking, “Wow, there’s not much I can do besides pick the frontier models.”
While that’s partly true, looking at the data closer, we can see that prompts, descriptions, and number of tools do have a meaningful impact on complex tasks.
Evaluating gpt-4o, we see this impact on complex task performance.
System Prompt | Tool Correctness | Task Completion |
|---|---|---|
Base | 44.1% | 37.5% |
Light | 51.2% | 42.9% |
Descriptive | 51.2% | 53.9% |
Description | Tool Correctness | Task Completion |
|---|---|---|
regular-detailed | 44.1% | 37.5% |
extra-detailed | 50% | 50% |
Not every setting will affect every model the same way. When we reference that varying number of tools is “beneficial for certain LLMs,” we can see that routing to sub-agents that have a smaller subset of tools positively impacts 3.5-Sonnet and not GPT-4o.
GPT-4o results:
Routing | Tool Correctness | Task Completion |
|---|---|---|
Routing | 73.3% | 55.8% |
No-Routing | 74.8% | 53.0% |
3.5-Sonnet results:
Routing | Tool Correctness | Task Completion |
|---|---|---|
Routing | 75.8% | 60.3% |
No-Routing | 67.6% | 65% |
In summary, using the newest frontier models is the best way to optimize tool calling. That part is more or less “science.” The “art” aspect of optimizing tool performance is fine-tuning for tool correctness and task completion as there is no “one” setting - “one prompt” or “one right number of tools” - that will optimize every model.
While there’s an evaluation method and a trial-and-error side of implementing tools, there’s also an engineering side that’s more cut-and-dry. Here are the engineering challenges that arise from scaling your agent’s tools.
Why agents struggle with tools at scale
It’s easy to forget that tools are still just tokens at the end of the day. LLMs decide when to call a tool based off the tool name, tool description, input names, and input descriptions. The code that makes up the tool/function call is run in your backend (NOT ran by the model provider). The result of the code is returned to the LLM.

The tool calling process means that:
Tool descriptions eat up tokens in the context window
Two round trips are required - one for the initial tool call intent and another for the tool call results
As you provide your agent with more and more capabilities in the form of tools, you must also reconcile with tools eating up your context window and breakdowns from too many tools.

This may be a bit extreme, as your product may not need more than 80 tools. However, filtering and tool selection will have performance and cost benefits. Let’s talk about how to engineer an agent system that can handle an increasing array of tools.
How to implement tools at scale
If tools eat up tokens and hog the context window, the fix is to load only the relevant tools. Here are a few designs that work:
Let users decide
How many times has one of your users said, “Whoa I didn’t know the product could do that!” You’ve probably experienced it yourself when you find a new iPhone setting or keyboard hotkey.
Letting users decide what tools to give your agent not only limits the number of tools, but also makes it apparent to your users what tools are available.
Using an example where an agent is using ActionKit to provide tools for different integration providers:

Multi-agent pattern
If you want your agent to decide on the right subset of tools needed to complete the user’s prompt, patterns like routing and orchestration can filter tools for your agent (3).
In the planner-worker implementation, a “planner” agent creates a plan on what integrations are necessary for the task. For example, if a user asks for their email inbox, the planner agent will respond with ['gmail'] . If a user asks about Salesforce and Gmail, the planner agent will respond with ['salesforce', 'gmail'] .
Based off the plan with a list of integrations, ActionKit builds tools dynamically - providing the right descriptions and input schema for different actions across an integration like Gmail.
A worker agent then uses only the integration-specific tools in its request to the OpenAI API.
End-to-end, the agent system loads only relevant tools based off the user prompt.
MCP provided tools
MCPs are similar to multi-agent patterns. Rather than a “planner” agent that lives in your application backend, an MCP server can decide on tools and dynamically provide them to your agent.
An important distinction here: MCP servers do NOT inherently provide tool selection out-of-the-box. The Model Context Protocol is a standard for providing your agent with prompts, sampling, and tools. MCP servers can help select tools, but the standard does not require an MCP server to.
In summary, don’t rely on 3rd-party MCP servers to solve tool selection for your agent. You can build your own MCP server that handles tool selection, or opt for an agent pattern like worker-planner to handle the MCP-provided tools.
Using Paragon’s ActionKit MCP server as an example, we used the same multi-agent pattern to plan and select tools, but what the ActionKit MCP server can uniquely do is provide server-specific context, such as magic links that authenticate users directly in the chat.

Check out the ActionKit MCP server to try out different 3rd-party integration tools right in your Cursor, Claude, or very own MCP client.
Wrapping Up
In this deep dive we went over:
Tool correctness and task completion as performance metrics
LLM choice as the #1 variable for improving performance, with additional fine-tuning improvements with prompts, descriptions, and routing
Context-window issues as tools scale
Patterns for dynamic tool loading
Tools present interesting challenges for AI product builders. Solving for these challenges is worth it, as tools equip agents with ways to interact with the outside world.
If you’d like to see how Paragon can help equip your AI product with integrations in your users’ world - like their Google Drive, Slack, Salesforce, and more - check out our use case page and book some time with our team.

Hungry for more AI deep dives and tutorials? Visit our learn page for more content like this!
Sources
DeepEval LLM Evaluation Metrics - https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
Paragon’s Guide to Optimizing Tool Calling - https://www.useparagon.com/learn/rag-best-practices-optimizing-tool-calling/
Vercel AI SDK’s Agent Guide - https://ai-sdk.dev/docs/foundations/agents#orchestrator-worker
CHAPTERS
TABLE OF CONTENTS
Table of contents will appear here.

Jack Mu
,
Devloper Advocate
mins to read
"/><stop offset="1" stop-color="rgb(145, 118, 251)"/></linearGradient><linearGradient id="ozqTbFI9H-1807422454-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgba(97, 64, 229, 0.16)"/><stop offset="1" stop-color="rgb(145, 118, 251)"/></linearGradient><linearGradient id="pE26o4gxW-1807422454-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgba(97, 64, 229, 0.16)"/><stop offset="1" stop-color="rgb(145, 118, 251)"/></linearGradient><linearGradient id="HHOgKLOd0-1807422454-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgba(97, 64, 229, 0.16)"/><stop offset="1" stop-color="rgb(145, 118, 251)"/></linearGradient></defs><path d="M 6.434 119.935 C 2.798 117.846 0.98 116.802 0.383 115.445 C -0.138 114.262 -0.127 112.912 0.413 111.738 C 1.033 110.391 2.866 109.376 6.535 107.346 L 186.592 7.74 C 194.253 3.502 198.084 1.383 202.139 0.552 C 205.728 -0.184 209.429 -0.184 213.018 0.552 C 217.073 1.383 220.903 3.502 228.565 7.741 L 408.621 107.346 C 412.29 109.376 414.124 110.391 414.744 111.738 C 415.284 112.912 415.295 114.262 414.774 115.445 C 414.176 116.802 412.358 117.846 408.723 119.935 L 229.174 223.08 C 221.305 227.6 217.37 229.861 213.189 230.746 C 209.489 231.529 205.667 231.529 201.967 230.746 C 197.786 229.861 193.852 227.6 185.982 223.08 Z" fill="url(%23lhM4UE7y4-1807422454-linear-gradient)" height="231.33281694397522px" id="lhM4UE7y4" transform="translate(5 0)" width="415.15720989312115px"/><path d="M 3.528 66.547 C 2.242 65.781 1.598 65.398 1.131 64.869 C 0.717 64.4 0.406 63.851 0.215 63.257 C 0 62.585 0 61.837 0 60.339 L 0 9.188 C 0 5.09 0 3.041 0.86 1.854 C 1.611 0.818 2.765 0.15 4.037 0.016 C 5.495 -0.14 7.272 0.881 10.825 2.922 L 190.662 106.233 C 198.532 110.754 202.466 113.014 206.647 113.899 C 210.347 114.682 214.169 114.682 217.869 113.899 C 222.05 113.014 225.985 110.754 233.854 106.233 L 413.691 2.922 C 417.245 0.881 419.022 -0.14 420.479 0.016 C 421.75 0.15 422.905 0.819 423.655 1.854 C 424.516 3.041 424.516 5.09 424.516 9.188 L 424.516 64.78 C 424.516 66.303 424.516 67.065 424.294 67.746 C 424.098 68.349 423.777 68.904 423.352 69.375 C 422.871 69.907 422.211 70.286 420.89 71.045 L 234.252 178.262 C 226.245 182.862 222.242 185.162 217.992 186.041 C 214.232 186.818 210.35 186.787 206.602 185.95 C 202.367 185.005 198.4 182.642 190.467 177.915 L 3.527 66.547 Z" fill="url(%23ozqTbFI9H-1807422454-linear-gradient)" height="186.6011677519727px" id="ozqTbFI9H" transform="translate(0 153)" width="424.51599999999996px"/><path d="M 3.528 66.546 C 2.242 65.78 1.598 65.396 1.131 64.867 C 0.717 64.399 0.406 63.85 0.215 63.256 C 0 62.584 0 61.835 0 60.338 L 0 9.188 C 0 5.09 0 3.04 0.86 1.854 C 1.611 0.818 2.765 0.15 4.037 0.016 C 5.495 -0.14 7.272 0.881 10.825 2.922 L 190.662 106.232 C 198.532 110.752 202.466 113.013 206.647 113.898 C 210.347 114.681 214.169 114.681 217.869 113.898 C 222.05 113.013 225.985 110.752 233.854 106.232 L 413.691 2.922 C 417.245 0.881 419.022 -0.14 420.479 0.016 C 421.75 0.15 422.905 0.819 423.655 1.854 C 424.516 3.04 424.516 5.09 424.516 9.188 L 424.516 64.778 C 424.516 66.302 424.516 67.063 424.294 67.745 C 424.098 68.347 423.777 68.902 423.352 69.373 C 422.871 69.905 422.211 70.285 420.89 71.044 L 234.252 178.261 C 226.245 182.861 222.242 185.161 217.992 186.039 C 214.232 186.816 210.35 186.785 206.602 185.949 C 202.367 185.003 198.4 182.64 190.467 177.914 L 3.527 66.546 Z" fill="url(%23pE26o4gxW-1807422454-linear-gradient)" height="186.5992791581399px" id="pE26o4gxW" transform="translate(0 261)" width="424.51599999999996px"/><path d="M 3.528 62.172 C 2.242 61.406 1.598 61.023 1.131 60.494 C 0.717 60.026 0.406 59.477 0.215 58.882 C 0 58.21 0 57.462 0 55.965 L 0 9.1 C 0 5.067 0 3.051 0.848 1.87 C 1.588 0.84 2.727 0.168 3.987 0.019 C 5.43 -0.151 7.195 0.825 10.724 2.777 L 191.044 102.529 C 198.785 106.811 202.655 108.952 206.749 109.779 C 210.373 110.511 214.109 110.494 217.726 109.729 C 221.812 108.864 225.663 106.688 233.364 102.335 L 305.348 61.648 C 308.891 59.646 310.662 58.645 312.114 58.807 C 313.38 58.948 314.528 59.618 315.274 60.65 C 316.129 61.834 316.129 63.869 316.129 67.939 L 316.129 121.417 C 316.129 122.925 316.129 123.679 315.911 124.355 C 315.718 124.953 315.403 125.505 314.984 125.974 C 314.512 126.504 313.861 126.886 312.561 127.649 L 234.368 173.545 C 226.323 178.267 222.301 180.628 218.019 181.542 C 214.231 182.351 210.313 182.338 206.53 181.505 C 202.254 180.563 198.247 178.175 190.233 173.401 Z" fill="url(%23HHOgKLOd0-1807422454-linear-gradient)" height="182.13937459493218px" id="HHOgKLOd0" transform="translate(0 369.5)" width="316.1290000000001px"/></svg>)

